Sistemi sensoriali/Sistema visivo/Elaborazione del segnale e Percezione di movimento e colore
Questa pagina è orfana, ovvero priva di collegamenti in entrata da altre risorse. Inseriscine almeno uno e rimuovi l'avviso. |
Introduzione
Sistema visivo
Sistema uditivo
Sistema somatosensoriale
Sistema gustativo
Sistema vestibolare
Elaborazione dei segnali nel sistema visivo modifica
I capitoli precedenti hanno fornito una comprensione più solida di alcuni dei concetti più importanti dell'elaborazione dei segnali nel sistema visivo. Resta ancora da analizzare la comprensione, o percezione, delle informazioni sensoriali elaborate, l'ultimo importante pezzo del puzzle. La percezione visiva è il processo di traduzione delle informazioni ricevute dagli occhi in una comprensione dello stato esterno delle cose. Ci rende consapevoli del mondo che ci circonda e ci permette di comprenderlo meglio. Sulla base della percezione visiva impariamo modelli che poi applicheremo più avanti nella vita e prendiamo decisioni basate su questo e sulle informazioni che ne ricaviamo. In altre parole, la nostra sopravvivenza dipende dalla percezione del mondo esterno. Il settore della percezione visiva è stato diviso in diversi sotto-settori, a causa del fatto che l'elaborazione è troppo complessa e richiede diversi meccanismi specializzati per percepire ciò che si vede. Questi sotto-settori includono: Percezione del colore, Percezione del movimento, Percezione della profondità, e Riconoscimento del volto, ecc.
Gerarchie profonde nella corteccia visiva dei primati modifica

Nonostante la sempre maggiore potenza di calcolo dei sistemi elettronici, ci sono ancora molti compiti in cui gli animali e gli esseri umani sono di gran lunga superiori ai computer. Uno di questi è la percezione e la contestualizzazione delle informazioni. Il computer classico, sia quello di un telefono che un supercomputer che occupa l'intera stanza, è essenzialmente un calcolatore di numeri. Può eseguire una quantità incredibile di calcoli in una minuscola quantità di tempo. Ciò che gli manca è la capacità di astrarre a partire dalle informazioni con cui sta lavorando. Collegando una macchina fotografica al computer, l'immagine che questo "percepisce" è solo una griglia di pixel, una matrice bidimensionale di numeri. Un umano riconoscerebbe immediatamente la geometria della scena, gli oggetti nell'immagine, e forse anche il contesto di ciò che sta accadendo. Questa nostra capacità è fornita da un macchinario biologico dedicato - il sistema visivo del cervello. Esso elabora tutto ciò che vediamo in modo gerarchico, partendo dalle caratteristiche più semplici dell'immagine per andare a quelle più complesse, fino alla classificazione degli oggetti in categorie. Per questo si dice che il sistema visivo ha una gerarchia profonda. La profonda gerarchia del sistema visivo dei primati ha ispirato gli scienziati informatici a creare modelli di reti neurali artificiali, i quali sono caratterizzati, tra il resto, da diversi strati in cui ciascuno di essi crea generalizzazioni di ordine maggiore dei dati di input.
Circa la metà della neocorteccia umana è dedicata alla visione. L'elaborazione delle informazioni visive avviene su almeno dieci livelli funzionali. I neuroni nelle prime aree visive estraggono semplici caratteristiche dell'immagine su piccole regioni locali dello spazio visivo. Man mano che le informazioni vengono trasmesse alle aree visive superiori, i neuroni rispondono a caratteristiche sempre più complesse. Con livelli più alti di elaborazione delle informazioni le rappresentazioni diventano più invarianti - meno sensibili alla dimensione esatta della caratteristica, alla rotazione o alla posizione. Inoltre, la dimensione del campo recettivo dei neuroni nelle aree visive superiori aumenta, indicando che sono dedicati a caratteristiche dell'immagine di scala più globale. Questa struttura gerarchica permette un calcolo efficiente, in quanto diverse aree visive superiori possono utilizzare le stesse informazioni calcolate nelle aree inferiori. La descrizione generica della scena fatta nelle prime aree visive è usata da altre parti del cervello per completare svariati compiti, come il riconoscimento e la categorizzazione degli oggetti, la presa, la manipolazione, la pianificazione del movimento, ecc.
Visione sotto-corticale modifica
L'elaborazione neurale delle informazioni visive inizia già prima che il segnale raggiunga qualunque struttura corticale. I fotorecettori sulla retina rilevano la luce e inviano segnali alle cellule gangliari della retina. La dimensione del campo recettivo di un fotorecettore è di un centesimo di grado (un campo recettivo grande un grado è più o meno la dimensione di un pollice, quando si ha il braccio teso in fronte a sé). Il numero di ingressi di una cellula gangliare, e quindi la dimensione del suo campo recettivo, dipende dalla posizione - nel centro della retina riceve segnali da un minimo di cinque recettori, mentre nella periferia una singola cellula può avere diverse migliaia di ingressi. Questo implica che la massima risoluzione spaziale è al centro della retina, chiamata anche fovea. Grazie a questa proprietà i primati possiedono un meccanismo di controllo dello sguardo che dirige la vista in modo che le caratteristiche di interesse siano proiettate sulla fovea.
Le cellule gangliari sono selettivamente sintonizzate per rilevare varie caratteristiche dell'immagine, come il contrasto di luminanza, il contrasto di colore, la direzione e la velocità del movimento. Tutte queste caratteristiche sono le informazioni primarie utilizzate più avanti nella sequenza di elaborazione del segnale. Se ci sono stimoli visivi che non sono rilevabili dalle cellule gangliari, allora essi non sono nemmeno rilevabili da nessuna area visiva corticale.
Le cellule gangliari inviano il segnale verso una regione del talamo chiamata nucleo genicolato laterale (lateral geniculate nucleus, LGN), che a sua volta trasmette i segnali alla corteccia. Non vi sono informazioni che indichino la presenza di un’elaborazione significativa nel LGN – vi è quasi una corrispondenza uno-a-uno tra le cellule gangliari della retina e il LGN. Tuttavia, solo il 5% degli input di quest’ultimo provengono dalla retina - tutti gli altri sono proiezioni di feedback corticali. Anche se il sistema visivo è spesso considerato come un sistema feed-forward, le connessioni ricorrenti di feedback così come le connessioni laterali sono una caratteristica comune a tutta la corteccia visiva. Il ruolo del feedback non è ancora pienamente compreso, ma si propone di attribuirlo a processi come l'attenzione, l'aspettazione, l'immaginazione e la compilazione delle informazioni mancanti.
Visione corticale modifica

La corteccia visiva può essere divisa in tre grandi parti: occipitale, dorsale e ventrale. La parte occipitale, che riceve l'input dal LGN e invia gli output alle vie dorsale e ventrale. Questa parte comprende le aree V1-V4 e medio temporale (MT), che elaborano diversi aspetti dell'informazione visiva, e dà origine a una rappresentazione generica della scena. La corrente dorsale è coinvolta nell'analisi dello spazio e nella pianificazione dell'azione. La corrente ventrale è invece coinvolta nel riconoscimento e nella categorizzazione degli oggetti.
La V1 è la prima area corticale che elabora le informazioni visive. Essa è sensibile a bordi, reticoli, terminazioni di linea, movimento, colore e disparità (intesa come differenza angolare tra le proiezioni di un punto sulla retina destra e sinistra). L’esempio più diretto dell'elaborazione gerarchica bottom-up è la combinazione lineare degli input di svariate cellule gangliari con campi recettivi di tipologia “center-surround” (le aree a confronto sono il centro del campo recettivo e la sua periferia) per creare una rappresentazione di una barra. Questo viene fatto dalle cellule semplici della V1 ed è stato descritto per la prima volta dagli eminenti neuroscienziati Hubel e Wiesel. Questo tipo di integrazione delle informazioni implica che le cellule semplici sono sensibili all'esatta posizione della barra e hanno un campo recettivo relativamente piccolo. Le cellule complesse della V1 ricevono input dalle cellule semplici, e sebbene rispondano a modelli lineari orientati, non sono sensibili all'esatta posizione della barra e hanno un campo recettivo più ampio. La computazione che figura in questo livello potrebbe essere un'operazione simile ad una MAX, che produce risposte simili in ampiezza alla più grande delle risposte relative ai singoli stimoli. Alcune cellule semplici e complesse possono anche rilevare la fine di una barra, e una frazione di cellule V1 sono anche sensibili al movimento locale all'interno dei loro rispettivi campi recettivi.
L'area V2 presenta una rappresentazione dei contorni più sofisticata, che comprende contorni definiti dalla texture, contorni illusori e contorni con proprietà di confine. V2 inoltre si basa sul rilevamento della disparità assoluta (si faccia riferimento alla definizione di disparità illustrata nel paragrafo precedente) in V1 e presenta cellule che sono sensibili alla disparità relativa, che è la differenza tra le disparità assoluta di due punti nello spazio. L'area V4 riceve input dalla V2 e dall'area V3, ma si sa molto poco del calcolo che avviene nella V3. L'area V4 presenta neuroni che sono sensibili a contorni con diversa curvatura e vertici con angoli particolari. Un'altra caratteristica importante è la codifica della tonalità di colore, che è invariante alla luminanza (luminance-invariant hue). Questa è in contrasto con la codifica elaborata in V1, dove i neuroni rispondono alla contrapposizione del colore lungo i due assi principali (rosso-verde e giallo-blu), piuttosto che al colore effettivo. La V4 ha altre uscite verso il flusso ventrale, verso la corteccia temporale inferiore (inferior temporal cortex, IT), che si è dimostrato attraverso studi di lesione essere essenziale per il riconoscimento degli oggetti.
La corteccia temporale inferiore: il riconoscimento degli oggetti modifica
La corteccia IT è divisa in due aree: TEO e TE. L'area TEO integra le informazioni sulle forme e le posizioni relative di più elementi di contorno e presenta per lo più cellule che rispondono a combinazioni semplici di caratteristiche. La dimensione del campo recettivo dei neuroni TEO è di circa 3-5 gradi. L'area TE presenta cellule con campi recettivi significativamente più grandi (10-20 gradi) che rispondono a volti, mani e configurazioni di caratteristiche complesse. Le cellule in TE rispondono alle caratteristiche visive che sono una generalizzazione più semplice dell'oggetto di interesse ma più complesse di semplici barre o macchie. Questo è stato dimostrato utilizzando un metodo di riduzione dello stimolo da Tanaka et al., dove prima viene misurata una risposta ad un oggetto e poi questo ultimo viene sostituito da rappresentazioni più semplici fino a quando la caratteristica fondamentale a cui i neuroni di TE rispondono viene circoscritta.
Sembra che i neuroni di TE mettano insieme varie caratteristiche di media complessità dai livelli inferiori della corrente ventrale per costruire modelli di parti di oggetti. I neuroni in TE che sono selettivi per oggetti specifici devono soddisfare due requisiti apparentemente contraddittori - selettività e invarianza. Essi devono distinguere tra diversi oggetti per mezzo della sensibilità alle caratteristiche nelle immagini retiniche. Tuttavia, lo stesso oggetto può essere visto da diverse angolazioni e distanze diverse in condizioni di luce diverse, producendo immagini retiniche molto dissimili nei vari casi. Per trattare tutte queste immagini come equivalenti, occorre ricavare delle caratteristiche invarianti che siano robuste contro certe trasformazioni, come i cambiamenti di posizione, illuminazione, dimensione sulla retina, ecc. I neuroni dell'area TE mostrano invarianza alla posizione e alle dimensioni, così come all'occlusione parziale, alla posizione nella profondità e alla direzione dell'illuminazione. La rotazione in profondità ha dimostrato di avere l'invarianza più debole, ad eccetto del caso in cui l'oggetto è un volto umano.
Le categorie di oggetti non sono ancora esplicitamente presenti nell'area TE - un neurone potrebbe rispondere tipicamente a diversi esemplari della stessa categoria, ma non a tutti (per esempio, immagini di alberi) e potrebbe anche rispondere a esemplari di categorie diverse (per esempio, alberi e non alberi). Il riconoscimento e la classificazione degli oggetti molto probabilmente implica il campionamento da una più ampia popolazione di neuroni TE, oltre a ricevere input da ulteriori aree cerebrali, ad esempio quelle che sono responsabili della comprensione del contesto della scena. Recenti esperimenti di lettura hanno dimostrato che i classificatori statistici (ad esempio le support vector machines) possono essere addestrati a classificare gli oggetti sulla base delle risposte di un piccolo numero di neuroni TE. Pertanto, una popolazione di neuroni TE in principio può segnalare in modo affidabile le categorie di oggetti grazie alla loro attività combinata. È interessante notare che è stata anche riportata la presenza di neuroni altamente selettivi nel lobo temporale mediale che rispondono a spunti (cues) molto specifici, ad esempio, alla torre di Pisa in immagini diverse o al volto di una particolare persona.
L'apprendimento nel sistema visivo modifica
L'apprendimento può alterare la selettività delle caratteristiche visive dei neuroni, con il suo effetto più forte ai livelli gerarchici più alti. Non vi sono prove note riguardo l’apprendimento nella retina e anche le mappe di orientamento nella V1 sembrano essere geneticamente predeterminate. Tuttavia, identificare l'orientamento migliora la codifica dello stesso nei neuroni della V1, aumentando la pendenza della curva di sintonizzazione. Effetti simili ma maggiori sono stati osservati in V4. Nell'area TE un allenamento visivo relativamente piccolo ha effetti fisiologici notevoli sulla percezione visiva, sia a livello di singola cellula che in fMRI. Per esempio, la trasformazione di due oggetti l'uno nell'altro aumenta la somiglianza percepita tra essi. Nel complesso sembra che anche la corteccia visiva adulta sia considerevolmente plastica, e che il livello di plasticità può essere significativamente aumentato, per esempio, somministrando farmaci specifici o vivendo in un ambiente arricchito.
Reti neurali (Deep neural networks) modifica
Analogamente alla profonda gerarchia del sistema visivo dei primati, le architetture di apprendimento (deep learning) tentano di modellare astrazioni di alto grado dei dati di input utilizzando più livelli di trasformazioni non lineari. Il modello proposto da Hubel e Wiesel, in cui le informazioni sono integrate e propagate in cascata dalla retina e dal LGN alle cellule semplici e complesse nella V1, ha ispirato la creazione di una delle prime architetture di apprendimento profondo, il neocognitron - un modello di rete neurale artificiale multistrato. Questo è stato utilizzato per diversi compiti di riconoscimento di schemi, compreso il riconoscimento di caratteri scritti a mano. Tuttavia, ci voleva molto tempo per addestrare la rete (nell'ordine di giorni) e dal suo inizio negli anni '80 l'apprendimento profondo non ha ottenuto molta attenzione fino alla metà degli anni 2000, con l'abbondanza di dati digitali e l'invenzione di algoritmi di allenamento più veloci. Le reti neurali si sono dimostrate essere molto efficaci in compiti che non molto tempo fa sembravano possibili solo per gli esseri umani, come riconoscere i volti di persone in foto, la comprensione del parlato umano (in una certa misura) e la traduzione di testi da lingue straniere. Inoltre, hanno dimostrato di essere di grande aiuto nell'industria e nella scienza per cercare potenziali candidati a farmaci, mappare vere reti neurali nel cervello e prevedere le funzioni delle proteine. Bisogna notare che il deep learning è solo molto vagamente ispirato al cervello ed è molto più una conquista nel campo dell'informatica e del machine learning che delle neuroscienze. I più semplici parallelismi che si possono notare sono che le reti neurali profonde sono composte da unità che integrano le informazioni di input in modo non lineare, come i neuroni, e inviano segnali l'uno all'altro, come le sinapsi, e che ci sono diversi livelli di rappresentazioni dei dati, sempre più astratte. Gli algoritmi di apprendimento e le descrizioni matematiche dei "neuroni" utilizzati nel deep learning sono molto diversi dai processi reali che avvengono nel cervello. Pertanto, la ricerca in questo ambito, pur dando un'enorme spinta a un'intelligenza artificiale più sofisticata, può solo dare intuizioni limitate sul cervello.
 |
 |

Riferimenti bibliografici per il capitolo modifica
- Articoli accademici sulle gerarchie profonde nel sistema visivo
- N. Kruger, P. Janssen, S. Kalkan, M. Lappe, A. Leonardis, J. Piater, A. J. Rodriguez-Sanchez e L. Wiskott, Deep Hierarchies in the Primate Visual Cortex: What Can We Learn for Computer Vision?, in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 35, n. 8, August 2013, pp. 1847–1871, DOI:10.1109/TPAMI.2012.272.
- Tomaso Poggio e Maximilian Riesenhuber, Nature Neuroscience, vol. 2, n. 11, 1º November 1999, pp. 1019–1025, DOI:doi:10.1038/14819, https://oadoi.org/doi:10.1038/14819.
- Esperimento di riduzione dello stimolo
- Keiji Tanaka, Inferotemporal Cortex and Object Vision, in Annual Review of Neuroscience, vol. 19, n. 1, March 1996, pp. 109–139, DOI:10.1146/annurev.ne.19.030196.000545.
- Prove dell’apprendimento nel sistema visivo
- Nuo Li e James J. DiCarlo, Unsupervised Natural Visual Experience Rapidly Reshapes Size-Invariant Object Representation in Inferior Temporal Cortex, in Neuron, vol. 67, n. 6, 23 September 2010, pp. 1062–1075, DOI:10.1016/j.neuron.2010.08.029.
- S. Raiguel, R. Vogels, S. G. Mysore e G. A. Orban, Learning to See the Difference Specifically Alters the Most Informative V4 Neurons, in Journal of Neuroscience, vol. 26, n. 24, 14 June 2006, pp. 6589–6602, DOI:10.1523/JNEUROSCI.0457-06.2006.
- A Schoups, R Vogels, N Qian e G Orban, Practising orientation identification improves orientation coding in V1 neurons., in Nature, vol. 412, n. 6846, 2 August 2001, pp. 549-53, PMID 11484056.
- Un resoconto accessibile e relativamente recente riguardo lo stato corrente della ricerca nel tema del deep learning
- Nicola Jones, Computer science: The learning machines, in Nature, vol. 505, n. 7482, 8 January 2014, pp. 146–148, DOI:10.1038/505146a.
Percezione del movimento modifica
La percezione del movimento è il processo di deduzione della velocità e della direzione degli oggetti in movimento. L'area visiva V5 negli esseri umani e l'area medio temporale (MT) nei primati sono responsabili della percezione del movimento. L'area V5 fa parte della corteccia extrastriata, che è la regione nella regione occipitale del cervello accanto alla corteccia visiva primaria. La funzione dell'area V5 è quella di rilevare la velocità e la direzione degli stimoli visivi, e di integrare i segnali visivi locali di movimento nel movimento globale. L'area V1 o corteccia visiva primaria si trova nel lobo occipitale del cervello in entrambi gli emisferi. Processa il primo stadio dell’elaborazione corticale delle informazioni visive. Quest'area contiene una mappa completa del campo visivo che viene coperto dagli occhi. La differenza tra l'area V5 e l'area V1 è che la prima può integrare il movimento di segnali locali o di singole parti di un oggetto in un movimento globale di un intero oggetto. L'area V1, invece, risponde al movimento locale che si verifica all'interno del campo recettivo. Le risposte che questi ultimi neuroni elaborano vengono integrate nell’area V5.
Il movimento è definito come cambiamenti nell'illuminazione retinica nello spazio e nel tempo. I segnali di movimento sono classificati in movimenti di primo ordine e movimenti di secondo ordine. Questi tipi di movimento sono brevemente descritti nei paragrafi seguenti.

Per percezione del movimento di primo ordine si fa riferimento al movimento percepito quando due o più stimoli visivi si accendono e si spengono nel tempo. Il movimento di primo ordine è anche definito "movimento apparente" ed è usato in televisione e nei film. Un esempio è il "movimento Beta", un'illusione in cui immagini fisse sembrano muoversi, anche se non si muovono in realtà. Queste immagini danno l'apparenza di movimento, perché cambiano e si muovono più velocemente di quello che l'occhio può rilevare. Questa illusione ottica avviene perché il nervo ottico umano risponde ai cambiamenti di luce a dieci cicli al secondo, quindi qualsiasi cambiamento più veloce di questa velocità sarà registrato come un movimento continuo e non come immagini separate.
Per movimento di secondo ordine si fa riferimento al movimento che si verifica quando un contorno che si sta muovendo è definito dal contrasto, dalla texture, da uno sfarfallio di luce o qualche altra qualità che non comporta un aumento della luminanza o dell'energia di movimento dell'immagine. L'evidenza suggerisce che le elaborazioni iniziali del movimento di primo e di secondo ordine sono effettuate da percorsi separati. I meccanismi del secondo ordine hanno una risoluzione temporale più scarsa e sono passa-basso in termini di gamma di frequenze spaziali a cui rispondono. Il movimento di secondo ordine produce un più debole effetto collaterale di movimento. I segnali del primo e del secondo ordine sono combinati nella V5.
In questo capitolo, analizzeremo i concetti di percezione del movimento e analisi del movimento, e spiegheremo la ragione per cui questi termini non dovrebbero essere usati in modo intercambiabile. Analizzeremo i meccanismi con cui viene percepito il movimento, come i sensori di movimento e il tracking delle caratteristiche. Esistono tre principali modelli teorici che tentano di descrivere la funzione dei sensori neuronali di movimento. Test sperimentali sono stati condotti per confermare se questi modelli sono accurati. Sfortunatamente, i risultati di questi test sono inconcludenti, e si può dire che nemmeno uno di questi descrive interamente il funzionamento dei sensori di movimento. Tuttavia, ciascuno di questi modelli simula alcune caratteristiche di questi. Vengono descritte alcune proprietà di questi sensori. Infine, questo capitolo mostra alcune illusioni di movimento, che dimostrano che il nostro senso del movimento può essere ingannato da fattori esterni statici che stimolano i sensori di movimento come farebbe il movimento vero e proprio.
Analisi del movimento e percezione del movimento modifica
I concetti di analisi del movimento e percezione del movimento sono spesso confusi come intercambiabili. Percezione del movimento e analisi del movimento sono importanti l'uno per l'altro, ma diversi.
L'analisi del movimento si riferisce all’insieme di meccanismi tramite cui vengono elaborati i segnali di movimento. In modalità simile a quella in cui la percezione del movimento non dipende necessariamente dai segnali generati dal movimento delle immagini nella retina, l'analisi del movimento può portare o meno alla percezione del movimento. Un esempio di questo fenomeno è la Vection, che si verifica nel caso in cui una persona percepisce di essere in movimento quando invece è ferma, ma l'oggetto che osserva è in movimento. La Vection dimostra come il movimento di un oggetto possa essere analizzato, senza venir necessariamente percepito come movimento proveniente dall'oggetto. Questa definizione di analisi del movimento suggerisce che il movimento è una proprietà fondamentale dell'immagine. Nel campo visivo, esso viene analizzato in ogni punto. E i risultati di questa analisi sono utilizzati per ricavare informazioni percettive.
La percezione del movimento si riferisce al processo di acquisizione della conoscenza percettiva del movimento di oggetti e superfici in un'immagine. Il movimento è percepito da delicati sensori locali nella retina o attraverso il feature tracking. I sensori locali di movimento sono neuroni specializzati sensibili al movimento e analoghi ai sensori specializzati per il colore. Il feature tracking è un modo indiretto di percepire il movimento, e consiste nell'inferire il movimento dai cambiamenti nella posizione retinica degli oggetti nel tempo. Viene anche chiamato analisi del movimento di terzo ordine. Il feature tracking funziona focalizzando l'attenzione su un particolare oggetto e osservando come la sua posizione è cambiata nel tempo.
Sensori di movimento modifica
Il rilevamento del movimento è il primo stadio dell'elaborazione visiva, e avviene grazie a processi neurali specializzati, che rispondono alle informazioni riguardanti i cambiamenti locali di intensità delle immagini nel tempo. Il movimento viene percepito indipendentemente dalle altre proprietà dell'immagine in tutti i punti dell'immagine. È stato dimostrato che i sensori di movimento esistono, e operano localmente in tutti i punti dell'immagine. I sensori di movimento sono sensori neuronali dedicati, situati nella retina, che sono in grado di rilevare un movimento prodotto da due brevi e piccoli lampi di luce che sono così vicini che non potrebbero essere rilevati dal feature tracking. Esistono tre modelli principali che tentano di descrivere il modo in cui funzionano questi sensori specializzati. Questi modelli sono indipendenti l'uno dall'altro, e cercano di modellare caratteristiche specifiche della percezione del movimento. Anche se non ci sono prove sufficienti per sostenere che uno di questi modelli rappresenti il modo in cui il sistema visivo (in particolare i sensori di movimento) percepisce il movimento, essi comunque modellano correttamente alcune funzioni di questi sensori.

Il rilevatore di Reichardt
l rilevatore di Reichardt è usato per modellare il modo in cui i sensori di movimento rispondono ai segnali di movimento di primo ordine. Quando un oggetto si muove dal punto A del campo visivo al punto B, si generano due segnali: uno prima dell'inizio del movimento e un altro dopo che il movimento è stato completato. Questo modello percepisce questo movimento rilevando i cambiamenti di luminanza in un punto della retina e correlandoli con un cambiamento di luminanza in un altro punto vicino dopo un breve ritardo. Il rilevatore di Reichardt funziona in base al principio di correlazione (una relazione statistica che implica dipendenza). Esso interpreta il segnale di movimento tramite la correlazione spazio-temporale dei segnali di luminanza in punti vicini, e fa uso del fatto che due campi recettivi in punti diversi della traiettoria di un oggetto in movimento ricevono una versione spostata nel tempo dello stesso segnale - un modello di luminanza si muove lungo un asse, e il segnale in un punto dell'asse è una versione spostata nel tempo di un segnale precedente nell'asse. Il modello del rilevatore di Reichardt ha due rilevatori vicini separati nello spazio. I segnali di uscita dei rilevatori sono moltiplicati (correlati) nel modo seguente: un segnale moltiplicato per un secondo segnale che è la versione spostata nel tempo dell'originale. La stessa procedura viene ripetuta ma nella direzione inversa del movimento (il segnale che è stato sfasato nel tempo diventa il primo segnale e viceversa). Poi, si prende la differenza tra queste due moltiplicazioni e il risultato dà la velocità del movimento. La risposta del rilevatore dipende dalla fase, dal contrasto e dalla velocità dello stimolo. Sono necessari molti rilevatori sintonizzati a velocità diverse per codificare la velocità effettiva del modello. La prova sperimentale più convincente per questo tipo di rilevatore proviene da studi sul riconoscimento della direzione di obiettivi appena visibili.
Filtraggio dell'energia di movimento
Il Motion Energy Filter è un modello di sensori di movimento basato sul principio dei filtri invarianti di fase. Questo modello costruisce filtri spazio-temporali orientati nello spazio-tempo per corrispondere alla struttura dei modelli in movimento. Consiste in filtri separabili, nei quali i profili spaziali mantengono la stessa forma nel tempo ma sono scalati dal valore dei filtri temporali. I filtri di energia del movimento corrispondono alla struttura dei modelli in movimento sommando i filtri separabili. Per ogni direzione di movimento, vengono generati due filtri spazio-temporali: uno simmetrico (a barra) e uno asimmetrico (a bordo). La somma dei quadrati di questi filtri è chiamata energia di movimento. La differenza del segnale per le due direzioni è chiamata energia avversaria (opponent energy). Questo risultato viene poi diviso per la radice quadrata del risultato di un altro filtro, sintonizzato sul contrasto statico. Questa divisione viene eseguita per tenere conto dell'effetto del contrasto nel movimento. I filtri di energia di movimento possono modellare un certo numero di fenomeni di movimento, ma producono una misura indipendente dalla fase, che aumenta con la velocità, ma non forniscono di questa un valore affidabile.
Gradienti spazio-temporali

Questo modello di sensori di movimento è stato originariamente sviluppato nel campo della computer vision, e si basa sul principio che il rapporto tra la derivata temporale della luminosità dell'immagine e la derivata spaziale della luminosità dell'immagine sia la velocità del movimento. È importante notare che nei picchi e nelle depressioni dell'immagine, questo modello non calcolerà una risposta adeguata, perché la derivata del denominatore sarebbe zero. Per risolvere questo problema, si possono analizzare anche le derivate spaziali del primo ordine e di ordine superiore rispetto allo spazio e al tempo. I gradienti spazio-temporali sono un buon modello per determinare la velocità di movimento in tutti i punti dell'immagine.
I sensori di movimento sono selettivi all’orientamento modifica
Una delle proprietà dei sensori di movimento è la selettività dell'orientamento, che limita l'analisi del movimento a una sola dimensione. I sensori di movimento possono registrare il movimento solo in una dimensione lungo un asse ortogonale all'orientamento preferito del sensore. Uno stimolo che contiene caratteristiche di un singolo orientamento può essere visto muoversi solo in una direzione ortogonale all'orientamento dello stimolo. I segnali di movimento unidimensionali danno informazioni ambigue sul movimento di oggetti bidimensionali. Un secondo stadio di analisi del movimento è necessario per ottenere la vera direzione del movimento di un oggetto o di un modello bidimensionale (2-D). I segnali di movimento unidimensionali provenienti da sensori sintonizzati su orientamenti diversi sono combinati per produrre un segnale di movimento 2-D non ambiguo. L'analisi del movimento 2-D dipende da segnali provenienti da sensori locali ampiamente orientati così come da segnali provenienti da sensori strettamente orientati.
Tracciamento delle caratteristiche (Feature tracking) modifica
Un altro modo in cui percepiamo il movimento è attraverso il Feature Tracking. Il Feature Tracking consiste nell'analizzare se le caratteristiche locali di un oggetto hanno cambiato posizione o meno, e dedurre il movimento da questo cambiamento. In questa sezione, vengono menzionate alcune caratteristiche dei feature trackers.
I Feature trackers falliscono quando uno stimolo in movimento si verifica molto rapidamente. I Feature trackers hanno il vantaggio, rispetto ai sensori di movimento, di poter percepire il movimento di un oggetto anche se questo è alternato a intervalli vuoti, in cui non si verifica movimento. Essi possono anche separare queste due fasi (movimenti e intervalli vuoti). I sensori di movimento, d'altra parte, integrerebbero solo i vuoti con lo stimolo in movimento e vedrebbero un movimento continuo. I feature trackers invece operano sulle posizioni delle caratteristiche identificate. Per questo motivo, hanno una soglia di distanza minima che corrisponde alla precisione con cui le posizioni delle caratteristiche possono essere discriminate. I feature trackers non presentano effetti collaterali di movimento, che sono illusioni visive causate dall'adattamento visivo. Questi effetti si verificano quando, dopo aver osservato uno stimolo in movimento, un oggetto fermo sembra muoversi nella direzione opposta allo stimolo precedentemente osservato. È impossibile per questo meccanismo monitorare movimenti multipli in diverse parti del campo visivo e allo stesso tempo. D'altra parte, i movimenti multipli non sono un problema per i sensori di movimento, perché operano in parallelo in tutto il campo visivo.
Sono stati condotti esperimenti utilizzando le informazioni di cui sopra per raggiungere conclusioni interessanti sui feature trackers. Esperimenti con stimoli brevi hanno dimostrato che i modelli di colore e di contrasto ad alto contrasto non sono percepiti dai feature trackers ma dai sensori di movimento. Gli esperimenti con intervalli vuoti (intesi come gli intervalli di tempo in cui non si verifica movimento) hanno confermato che il feature tracking può avvenire con intervalli vuoti nel display. È solo ad alto contrasto che i sensori di movimento percepiscono il movimento degli stimoli cromatici e dei modelli di contrasto. A basso contrasto i feature tracker analizzano il movimento sia dei pattern cromatici che degli inviluppi di contrasto, mentre ad alto contrasto i sensori di movimento analizzano gli inviluppi di contrasto. Gli esperimenti in cui i soggetti esprimono giudizi multipli sul movimento suggeriscono che il feature tracking è un processo che avviene sotto controllo cosciente e che è l'unico modo che abbiamo per analizzare il movimento degli inviluppi di contrasto nei display a basso contrasto. Questi risultati sono coerenti con la visione che il movimento degli inviluppi di contrasto e dei modelli di colore dipende dal feature tracking, tranne quando i colori sono ben al di sopra della soglia o il contrasto medio è alto. La conclusione principale di questi esperimenti è che probabilmente è il feature tracking che permette la percezione degli inviluppi di contrasto e dei pattern di colore.
Illusioni di movimento modifica
Come conseguenza del processo in cui funziona il rilevamento del movimento, alcune immagini statiche potrebbero sembrarci in movimento. Queste danno un'idea delle assunzioni fatte dal sistema visivo, e sono chiamate illusioni visive.
Una famosa illusione di movimento legata ai segnali di movimento del primo ordine è il fenomeno Phi, un'illusione ottica che ci fa percepire il movimento invece che una sequenza di immagini. Questa illusione di movimento ci permette di guardare i film come un video continuo e non come una successione di immagini separate. Grazie al fenomeno Phi, un gruppo di immagini congelate che vengono cambiate ad una velocità costante viene visto come un movimento costante. Questo fenomeno non deve essere confuso con il Movimento Beta, perché il primo è un movimento apparente causato da impulsi luminosi in sequenza, mentre il secondo è un movimento apparente causato da impulsi luminosi fermi.
Le illusioni di movimento si verificano quando la percezione del movimento, l'analisi del movimento e l'interpretazione di questi segnali sono fuorvianti, e il nostro sistema visivo crea illusioni sul movimento. Queste illusioni possono essere classificate in base al processo che le permette. Le illusioni sono classificate come illusioni relative al rilevamento del movimento, all'integrazione 2D e all'interpretazione 3D.
Le illusioni più popolari riguardanti il rilevamento del movimento sono illusioni di movimento a quattro tempi (four-stroke motion), gli RDK (random dot kinematogram) e segnali di movimento del secondo ordine. Le illusioni di movimento più popolari riguardanti l'integrazione 2D sono la Motion Capture, la Plaid Motion e la Direct Repulsion. Allo stesso modo, quelle riguardanti l'interpretazione 3D sono la Transformational Motion, Kinetic Depth, Shadow Motion, Biological Motion, Stereokinetic motion, Implicit Figure Motion e 2 Stroke Motion. Ci sono molte altre illusioni di movimento, e tutte mostrano qualcosa di interessante riguardo ai meccanismi umani di rilevazione, percezione e analisi del movimento. Per maggiori informazioni, si visiti il seguente link: http://www.lifesci.sussex.ac.uk/home/George_Mather/Motion/
Problemi aperti modifica
Anche se non abbiamo ancora capito la maggior parte delle specificità riguardanti la percezione del movimento, la comprensione dei meccanismi con cui il movimento viene percepito così come l'illusione del movimento può dare al lettore una buona panoramica dello stato dell'arte in materia. Alcuni dei problemi aperti riguardanti la percezione del movimento sono i meccanismi di formazione delle immagini 3D nel movimento globale e il problema dell'apertura.
I segnali di movimento globale dalla retina sono integrati per arrivare a un segnale di movimento globale bidimensionale, tuttavia non è chiaro come si forma il movimento globale 3D. Il problema dell'apertura si verifica perché ogni campo recettivo nel sistema visivo copre solo una piccola parte del mondo visivo, il che porta ad ambiguità nella percezione. Il problema dell'apertura si riferisce al problema di un contorno in movimento che, quando viene osservato localmente, è coerente con varie possibilità di movimento. Questa ambiguità è di origine geometrica - il movimento parallelo al contorno non può essere rilevato, poiché i cambiamenti di questa componente del movimento non cambiano le immagini osservate attraverso l'apertura. L'unica componente che può essere misurata è la velocità ortogonale all'orientamento del contorno; per questo motivo, la velocità del movimento potrebbe essere una qualunque di quelle appartenenti alla famiglia dei movimenti lungo una linea nello spazio di velocità. Questo problema di apertura non si osserva solo nei contorni rettilinei, ma anche in quelli dolcemente curvi, poiché essi sono approssimativamente rettilinei quando vengono osservati localmente. Anche se i meccanismi per risolvere il problema dell'apertura sono ancora sconosciuti, esistono alcune ipotesi su come potrebbe essere risolto. Per esempio, si potrebbe combinare informazioni da vari punti dello spazio o da diversi contorni dello stesso oggetto.
Conclusioni modifica
In questo capitolo abbiamo introdotto la percezione del movimento e i meccanismi con cui il nostro sistema visivo rileva il movimento. Le illusioni di movimento hanno mostrato come i segnali di movimento possano essere fuorvianti, e di conseguenza portare a conclusioni errate sul movimento. È importante ricordare che la percezione del movimento e l'analisi del movimento non sono la stessa cosa. I sensori di movimento e i feature trackers si completano a vicenda per far sì che il sistema visivo percepisca il movimento stesso.
La percezione del movimento è complessa ed è ancora un'area di ricerca aperta. Questo capitolo descrive modelli sul modo in cui funzionano i sensori di movimento e ipotesi sulle caratteristiche del feature tracker; tuttavia, è necessario svolgere più esperimenti per apprendere le caratteristiche di questi meccanismi ed essere in grado di costruire modelli che assomiglino più accuratamente ai processi effettivi del sistema visivo.
I vari meccanismi di analisi e percezione del movimento descritti in questo capitolo, così come la raffinatezza dei modelli artificiali progettati per descriverli, dimostrano che il modo in cui la corteccia elabora i segnali dall'ambiente esterno è molto complesso. Migliaia di neuroni specializzati integrano e interpretano pezzi di segnali locali per formare immagini globali di oggetti in movimento nel nostro cervello. Il capire che così tanti elementi e processi nel nostro corpo devono lavorare in sintonia per percepire il movimento rende ancora più notevole la nostra capacità di farlo con tanta facilità.
La percezione del colore modifica
Gli esseri umani (insieme ai primati, come scimmie e gorilla) hanno la migliore percezione dei colori tra I mammiferi [1]. Non è quindi una coincidenza che il colore giochi un ruolo importante in una grande varietà di aspetti. Per esempio, è utile per discriminare e differenziare oggetti, superfici, scenari naturali e persino volti [2],[3]. Il colore è anche uno strumento importante per la comunicazione non verbale, compresa quella delle emozioni [4].
Per molti decenni, è stata una sfida trovare i legami tra le proprietà fisiche del colore e le sue qualità percettive. Di solito, questi sono studiati sotto due approcci diversi: la risposta comportamentale causata dal colore (chiamata anche psicofisica) e la risposta fisiologica reale causata da esso [5].
Qui ci concentreremo solo su quest'ultima. Lo studio delle basi fisiologiche della visione dei colori, di cui non si sapeva praticamente nulla prima della seconda metà del ventesimo secolo, è progredito lentamente e con costanza dal 1950. Sono stati fatti importanti progressi in molte aree, specialmente a livello dei recettori. Grazie ai metodi di biologia molecolare, è stato possibile rivelare dettagli precedentemente sconosciuti sulla base genetica dei pigmenti del cono. Inoltre, sempre più regioni corticali hanno dimostrato di essere influenzate dagli stimoli visivi, anche se la correlazione della percezione dei colori con l'attività fisiologica dipendente dalla lunghezza d'onda oltre i recettori non è così facile da discernere [6].
In questo capitolo, ci proponiamo di spiegare le basi dei diversi processi di percezione del colore nel percorso visivo, dalla retina nell'occhio alla corteccia visiva nel cervello. Per i dettagli anatomici, si prega di fare riferimento alla sezione "Anatomia del sistema visivo" di questo Wikibook.
Percezione del colore sulla retina modifica
Tutti i colori che possono essere discriminati dagli esseri umani possono essere prodotti dalla miscela di soli tre colori primari (di base). Ispirandosi a questa idea di miscelazione dei colori, è stato proposto che il colore sia servito da tre classi di sensori, ognuno dei quali ha una sensibilità massima a una parte diversa dello spettro visibile [1]. È stato proposto esplicitamente per la prima volta nel 1853 che ci sono tre gradi di libertà nella normale corrispondenza dei colori [7]. Questo fu poi confermato nel 1886 [8] (con risultati notevolmente vicini a quelli di studi più recenti [9], [10]).
Questi sensori di colore proposti sono in realtà i cosiddetti coni (Nota: In questo capitolo, ci occuperemo solo dei coni. I bastoncelli contribuiscono alla visione solo a bassi livelli di luce. Anche se sono noti avere un effetto sulla percezione del colore, la loro influenza è molto piccola e può essere qui ignorata) [11]. I coni sono uno dei due tipi di cellule fotorecettrici che si trovano nella retina, presenti in una concentrazione significativa nella fovea. La tabella qui sotto elenca i tre tipi di cellule del cono. Queste si distinguono per i diversi tipi di pigmento di rodopsina. Le loro curve di assorbimento corrispondenti sono mostrate nella figura qui sotto.
| Nome | Colore a massima sensibilità | Picco della curva di assorbimento [nm] |
|---|---|---|
| S, SWS, B | Blu | 420 |
| M, MWS, G | Verde | 530 |
| L, LWS, R | Rosso | 560 |
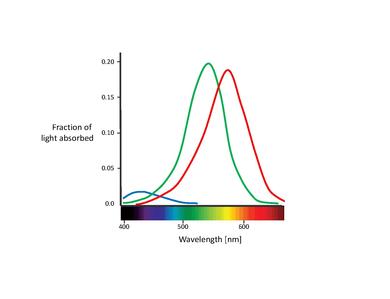
Sebbene non si sia raggiunto un consenso sulla denominazione dei diversi tipi di cono, le denominazioni più utilizzate si riferiscono o al loro picco di spettro d'azione o al colore a cui sono sensibili (rosso, verde, blu) [6]. In questo testo, useremo la designazione S-M-L (per lunghezza d'onda corta, media e lunga, dall'inglese short, medium, long), poiché questi nomi sono più propriamente descrittivi. La nomenclatura blu-verde-rosso è in qualche modo fuorviante, poiché tutti le tipologie di coni sono sensibili a una vasta gamma di lunghezze d'onda.
Una caratteristica importante dei tre tipi di coni è la loro distribuzione relativa nella retina. Risulta che i coni S presentano una concentrazione relativamente bassa sulla retina, essendo completamente assenti nell'area più centrale della fovea. In realtà, sono troppo distanziati per svolgere un ruolo importante nella visione spaziale, anche se sono in grado di mediare una debole percezione dei confini [12]. La fovea è dominata dai coni L e M. La proporzione di questi ultimi due è solitamente misurata sotto forma di un rapporto. Sono stati riportati diversi valori per il rapporto L/M, che vanno da 0,67 [13] fino a 2 [14], ma quest'ultimo è il più accettato. Il motivo per cui i coni L superano quasi sempre i coni M rimane poco chiaro. Sorprendentemente, il rapporto relativo dei coni non ha quasi nessun impatto significativo sulla visione dei colori. Questo dimostra chiaramente che il cervello è plastico, capace di dare un senso a qualsiasi segnale dei coni che riceva [15], [16].
È anche importante notare la sovrapposizione degli spettri di assorbimento dei coni L e M. Mentre lo spettro di assorbimento del cono S è chiaramente separato, i picchi del cono L e M sono distanti solo circa 30 nm e le loro curve spettrali si sovrappongono in modo significativo. Questo risulta in un'alta correlazione nelle cattura dei fotoni di queste due classi di coni. Ciò si spiega con il fatto che per ottenere la massima acuità possibile nel centro della fovea, il sistema visivo tratta i coni L e M allo stesso modo, non tenendo conto dei loro spettri di assorbimento. Pertanto, qualsiasi tipo di differenza porta a un deterioramento del segnale di luminanza [17]. In altre parole, la piccola separazione tra gli spettri dei coni L e M potrebbe essere interpretata come un compromesso tra la necessità di visione dei colori che sia ad alto contrasto e la visione della luminanza che sia ad alta acuità. Questo è congruente con la mancanza di coni S nella parte centrale della fovea, dove l'acuità visiva è maggiore. Inoltre, la stretta spaziatura degli spettri di assorbimento dei coni L e M potrebbe anche essere spiegata dalla loro origine genetica. Si presume che entrambi i tipi di cono si siano evoluti "recentemente" (circa 35 milioni di anni fa) da un antenato comune, mentre i coni S si sono presumibilmente separati dal recettore ancestrale molto prima [11].
Le funzioni di assorbimento spettrale dei tre diversi tipi di cellule coniche sono la caratteristica distintiva della visione dei colori negli umani. Questa teoria ha risolto un problema noto da tempo: anche se possiamo vedere milioni di colori diversi (gli esseri umani possono distinguere da 7 a 10 milioni di colori diversi [5]), le nostre retine semplicemente non hanno abbastanza spazio per ospitare un rilevatore individuale per ogni colore in ciascuna posizione retinica.
Dalla retina al cervello modifica
I segnali che vengono trasmessi dalla retina ai livelli superiori non sono semplici rappresentazioni puntuali dei segnali dei recettori, ma consistono piuttosto in sofisticate combinazioni di questi ultimi. L'obiettivo di questa sezione è di fornire una breve descrizione dei percorsi che alcune di queste informazioni prendono.
Una volta che l'immagine ottica sulla retina è trasdotta in segnali chimici ed elettrici dai fotorecettori, i segnali modulati in ampiezza sono convertiti in rappresentazioni modulate in frequenza ai livelli che vanno dalle cellule gangliari più in alto. In queste cellule neurali, la grandezza del segnale è rappresentata in termini di numero di picchi di tensione al secondo generati dalla cellula, piuttosto che dalla differenza di tensione attraverso la membrana cellulare. Per spiegare e rappresentare le proprietà fisiologiche di queste cellule, ci sarà molto utile il concetto di campo recettivo.
Il campo recettivo è la rappresentazione grafica dell'area nel campo visivo alla quale risponde una data cellula. Inoltre, la natura della risposta è tipicamente indicata per varie regioni nel campo recettivo. Per esempio, possiamo considerare il campo recettivo di un fotorecettore come una piccola area circolare che rappresenta la dimensione e la posizione della sensibilità di quel particolare recettore nel campo visivo. La figura sottostante mostra dei campi recettivi esemplari per le cellule gangliari, tipicamente in una contrapposizione centro-intorno. Il campo recettivo di sinistra nella figura illustra una risposta centrale positiva (nota come on-center, sul centro). Questo tipo di risposta è solitamente generato da una risposta positiva di un singolo cono, circondato da una risposta negativa generata da diversi coni vicini. Pertanto, la risposta di questa cellula gangliare sarebbe composta dalle risposte provenienti da vari coni, con segni sia positivi che negativi. In questo modo, la cellula non risponde solo ai punti di luce, ma serve come rilevatore di bordi (o più correttamente, di punti). In analogia con la terminologia della computer vision, possiamo pensare alle risposte delle cellule gangliari come al risultato di una convoluzione con un kernel di rilevamento dei bordi. Il campo recettivo destro della figura illustra una risposta centrale negativa (nota come off-center), che è altrettanto probabile. Di solito, le cellule on-center e off-center si presentano nella stessa posizione spaziale, alimentate dagli stessi fotorecettori, con conseguente aumento della gamma dinamica.
La figura sottostante mostra che oltre all'antagonismo spaziale, le cellule gangliari possono anche avere un antagonismo spettrale. Per esempio, la parte sinistra della figura inferiore illustra una risposta di contrapposizione rosso-verde, con il centro alimentato da una risposta positiva di un cono L e i dintorni alimentati da risposte negative di coni M. La parte destra della figura inferiore illustra invece la versione off-center di questa cellula. Quindi, prima ancora che l'informazione visiva abbia lasciato la retina, l'elaborazione è già avvenuta, con un profondo effetto sull'aspetto del colore. Ci sono altri tipi e varietà di risposte delle cellule gangliari, ma tutti condividono questi concetti di base.
 |
 |
 |
 |
Sulla loro strada verso la corteccia visiva primaria, gli assoni delle cellule gangliari si riuniscono per formare il nervo ottico, che proietta al nucleo genicolato laterale (lateral geniculate nucleus, LGN) nel talamo. La codifica nel nervo ottico è altamente efficiente, mantenendo il numero di fibre nervose al minimo (il numero è limitato dalla dimensione del nervo ottico) e quindi anche la dimensione del punto cieco retinico il più piccolo possibile (circa 5 gradi di larghezza per 7 gradi di altezza). Inoltre, le cellule gangliari presentate non avrebbero alcuna risposta all'illuminazione uniforme, poiché le aree positive e negative sono bilanciate. In altre parole, i segnali trasmessi non sono correlati. Per esempio, le informazioni provenienti da parti vicine di scene naturali sono altamente correlate spazialmente e quindi altamente prevedibili [18]. L'inibizione laterale tra cellule gangliari retiniche vicine minimizza questa correlazione spaziale, migliorando così l'efficienza. Possiamo interpretare questo come un processo di compressione dell'immagine effettuato nella retina.
Data la sovrapposizione degli spettri di assorbimento dei coni L e M, anche i loro segnali sono altamente correlati. In questo caso, l'efficienza della codifica viene migliorata combinando i segnali dei coni per minimizzare tale correlazione. Possiamo capire più facilmente questo utilizzando l'analisi delle componenti principali (principal component analysis, PCA). La PCA è un metodo statistico usato per ridurre la dimensionalità di un dato insieme di variabili trasformando le variabili originali in una combinazione di un insieme di nuove variabili, le componenti principali (PC). La prima PC rappresenta la massima varianza totale che era presente nelle variabili originali, la seconda PC rappresenta la massima varianza non rappresentata dal primo componente, e così via. Inoltre, le PC sono linearmente indipendenti e ortogonali tra loro nello spazio dei parametri. Il vantaggio principale della PCA è che già alcune delle PC più forti sono sufficienti a illustrare la maggior parte della variabilità del sistema [19]. Questo schema è stato utilizzato con le funzioni di assorbimento del cono [20] e anche con gli spettri naturali [21],[22]. Le PC che sono state trovate nello spazio di eccitazione del cono prodotti da oggetti naturali sono: 1) un asse di luminanza dove i segnali del cono L e M sono sommati (L+M), 2) la differenza dei segnali del cono L e M (L-M), 3) un asse di colore dove il segnale del cono S è differenziato dalla somma dei segnali del cono L e M (S-(L+M)). Questi canali, derivati da un approccio matematico/computazionale, coincidono con i tre canali retino-genicolati scoperti in esperimenti elettrofisiologici [23],[24]. Utilizzando questi meccanismi, l'informazione visiva ridondante viene eliminata a livello della retina.
Come appena menzionato, sono tre i canali di informazione che comunicano effettivamente queste informazioni dalla retina, attraverso le cellule gangliari, al LGN. Sono diversi non solo nelle loro proprietà cromatiche, ma anche nel loro substrato anatomico. Questi canali pongono importanti limitazioni per i compiti di base del colore, come il rilevamento e il riconoscimento.
Nel primo canale, l'uscita dei coni L e M è trasmessa sinergicamente alle cellule bipolari diffuse e poi alle cellule degli strati magnocellulari (M-) del LGN (da non confondere con i coni M della retina)[24]. I campi recettivi delle cellule M sono composti da un centro e un intorno, che sono spazialmente antagonisti. Le cellule M hanno una sensibilità ad alto contrasto per gli stimoli di luminanza, ma non mostrano alcuna risposta a certe combinazioni di ingressi opposti L-M [25]. Tuttavia, poiché i punti nulli delle diverse cellule M- variano leggermente, la risposta della popolazione non è mai veramente zero. Questa proprietà è effettivamente trasmessa alle aree corticali aventi input principalmente dalle cellule M-[26].
La via parvocellulare (P-) ha origine nelle uscite individuali dai coni L- o M- verso le cellule bipolari medie. Queste forniscono l'input alle cellule P della retina [11]. Nella fovea, i centri del campo recettivo delle cellule P sono formati da singoli coni L o M. La struttura dell'intorno del campo recettivo delle cellule P è ancora dibattuta. Tuttavia, la teoria più accettata afferma che il contorno è costituito da un tipo specifico di cono, risultando in un campo recettivo spazialmente opposto (che contrappone gli stimoli provenienti da diverse aree di spazio) per stimoli di luminanza [27]. Gli strati parvocellulari contribuiscono con circa l'80% delle proiezioni totali dalla retina al LGN [28].
Infine, la via koniocellulare (K-), di recente scoperta, trasporta soprattutto segnali dai coni S [29]. Gruppi di coni di questo tipo proiettano a speciali cellule bipolari, che a loro volta forniscono input a specifiche piccole cellule gangliari. Queste, di solito, non sono spazialmente opposte, e i loro assoni proiettano a sottili strati del LGN (adiacenti agli strati parvocellulari) [30].
Per quanto le cellule gangliari terminino nel LGN (facendo sinapsi con le cellule del LGN), sembra esserci una corrispondenza uno a uno tra le cellule gangliari e le cellule del LGN. Il LGN appare agire come una stazione di relè (stazione che irradia i segnali che riceve mantenendo ampiezza e frequenza, ma alterando la potenza) per i segnali. Tuttavia, probabilmente esso svolge una qualche funzione visiva, dato che ci sono proiezioni neurali dalla corteccia verso il LGN che potrebbero servire come una sorta di meccanismo di commutazione o feedback di adattamento. Gli assoni delle cellule del LGN proiettano all'area visiva uno (V1) nella corteccia visiva nel lobo occipitale.
Percezione del colore nel cervello modifica
Nella corteccia, le proiezioni delle vie magno-, parvo- e konio-cellulari terminano in diversi strati della corteccia visiva primaria. Le fibre magnocellulari innervano principalmente lo strato 4Cα e lo strato 6. I neuroni parvocellulari invece proiettano principalmente al 4Cβ e agli strati 4A e 6. Infine, i neuroni koniocellulari terminano nei blob ricchi di citocromo ossidasi (CO-) negli strati 1, 2 e 3 [31].
Una volta nella corteccia visiva, la codifica delle informazioni visive diventa significativamente più complessa. Nello stesso modo in cui le uscite di vari fotorecettori sono combinate e confrontate per produrre risposte delle cellule gangliari, le uscite di varie cellule LGN sono confrontate e combinate per produrre risposte corticali. Man mano che i segnali avanzano nella catena di elaborazione corticale, questo processo si ripete con un livello di complessità rapidamente crescente, al punto che i campi recettivi cominciano a perdere significato. Tuttavia, alcune funzioni e processi sono stati identificati e studiati in regioni specifiche della corteccia visiva.
Nella regione V1 (corteccia striata), i neuroni a doppia opponenza - neuroni che hanno i loro campi recettivi sia cromaticamente che spazialmente opposti rispetto alle regioni on/off di un singolo campo recettivo - confrontano i segnali di colore attraverso lo spazio visivo [32]. Esse costituiscono dal 5% al 10% delle cellule della V1. La loro grande dimensione e piccola percentuale rispetto alla totalità delle cellule comporta la scarsa risoluzione spaziale della visione dei colori [1]. Inoltre, non sono sensibili alla direzione degli stimoli in movimento (a differenza di alcuni altri neuroni della V1) e, quindi, è improbabile che contribuiscano alla percezione del movimento [33]. Tuttavia, data la loro struttura specializzata del campo recettivo, questo tipo di cellule sono la base neurale per gli effetti di contrasto del colore, nonché un mezzo efficiente per codificare il colore stesso [34],[35]. Altre cellule della V1 rispondono ad altre tipologie di stimoli, come i bordi orientati, svariate frequenze spaziali e temporali, specifiche posizioni spaziali, e combinazioni di queste caratteristiche, per nominarne alcune. Inoltre, possiamo trovare cellule che combinano linearmente gli input provenienti dalle cellule LGN, ma anche altre che eseguono una combinazione non lineare. Queste risposte sono necessarie per supportare capacità visive avanzate, come il colore stesso.

Ci sono notevolmente meno informazioni sulle proprietà cromatiche dei singoli neuroni nella V2 che nella V1. Ad un primo sguardo, sembra che non vi siano grandi differenze di codifica del colore tra V1 e V2 [36]. Un'eccezione a ciò è l'emergere di una nuova classe di cellule complesse del colore [37]. Pertanto, è stato suggerito che la regione V2 sia coinvolta nell'elaborazione della tonalità. Tuttavia, questo è ancora molto controverso e non è stato confermato.
Seguendo il concetto modulare sviluppato dopo la scoperta della dominanza oculare funzionale (functional ocular dominance) in V1, e considerando la segregazione anatomica tra le vie P, M e K (descritta nella sezione 3), è stato suggerito che dovrebbe esistere un sistema specializzato all'interno della corteccia visiva dedicato all'analisi delle informazioni sul colore [38]. La V4 è la regione che storicamente ha attirato la maggiore attenzione come possibile "area del colore" del cervello, a causa di un influente studio il quale sosteneva che essa contenesse il 100% di cellule tonalità-selettive [39]. Tuttavia, questa affermazione è stata contestata da una serie di studi successivi, alcuni dei quali riportano addirittura che solo il 16% dei neuroni della V4 mostra una sintonizzazione per la tonalità [40]. Attualmente, il concetto più accettato è che la V4 contribuisce non solo al colore, ma anche alla percezione della forma, all'attenzione visiva e alla stereopsi. Inoltre, studi recenti si sono concentrati su altre regioni cerebrali cercando di trovare la cosiddetta "area del colore" del cervello, come TEO (area locata sul collegamento tra la corteccia temporale e quella occipitale) [41] e la sub-divisione dorsale della corteccia temporale inferiore posteriore (dorsal subdivision of the posterior inferotemporal cortex, PITd) [42]. La relazione che queste regioni hanno tra loro è ancora dibattuta. Per conciliare la discussione, alcuni usano il termine corteccia temporale inferiore posteriore (posterior inferior temporal cortex, PIT) per indicare la regione che comprende V4, TEO e PITd [1].
Se la risposta corticale nelle cellule V1, V2 e V4 è già un'operazione molto complicata, il livello di complessità delle risposte visive complesse in una rete di circa 30 zone visive è enorme. La soprastante mostra una piccola parte della connettività delle diverse aree corticali (non cellule) che sono state identificate [43].
A questo punto, diventa estremamente difficile spiegare la funzione delle singole cellule corticali in termini semplici. In effetti, la funzione di una singola cellula potrebbe non avere significato, poiché la rappresentazione delle varie percezioni deve essere distribuita tra gruppi di cellule in tutta la corteccia.
Meccanismi di adattamento alla visione del colore modifica
Anche se i ricercatori hanno cercato di spiegare l'elaborazione dei segnali di colore nel sistema visivo umano, è importante capire che la percezione del colore non è un processo costante e che resta invariato. In realtà, ci sono svariati meccanismi dinamici che servono a ottimizzare la risposta visiva in base all'ambiente di osservazione. Di particolare rilevanza per la percezione del colore sono i meccanismi di adattamento al buio, alla luce e cromatico.
Adattamento al buio modifica
L'adattamento al buio si riferisce al cambiamento della sensibilità visiva che si verifica quando il livello di illuminazione è diminuito. La risposta del sistema visivo a un'illuminazione ridotta è quella di diventare più sensibile, aumentando la sua capacità di produrre una risposta visiva significativa anche quando le condizioni di luce non sono ottimali [44].
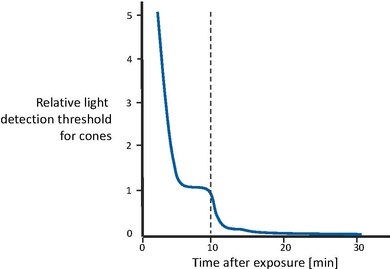
Nella figura a lato viene mostrato il recupero della sensibilità visiva dopo la transizione da un livello di illuminazione estremamente alto alla completa oscurità [43]. In un primo momento, i coni diventano gradualmente più sensibili, fino a quando la curva si livella dopo un paio di minuti. Poi, dopo circa 10 minuti, la sensibilità visiva è approssimativamente costante. A quel punto, il sistema dei bastoncelli, che ha un tempo di recupero più lungo, ha recuperato abbastanza sensibilità da superare i coni e quindi riprendere il controllo della sensibilità complessiva. Anche la sensibilità dei bastoncelli migliora gradualmente, fino a raggiungere il suo asintoto dopo circa 30 minuti. In altre parole, i coni sono responsabili del recupero della sensibilità per i primi 10 minuti. In seguito, i bastoncelli superano i coni e guadagnano la piena sensibilità dopo circa 30 minuti.
Questo è solo uno dei vari meccanismi neurali prodotti per adattarsi al meglio alle condizioni di bassa illuminazione. Altri meccanismi neurali includono il ben noto riflesso pupillare, l'esaurimento e la rigenerazione del fotopigmento, il controllo del guadagno nelle cellule retiniche e altri meccanismi di livello superiore, oltre che l'interpretazione cognitiva, per nominarne alcuni.
Adattamento alla luce modifica
L'adattamento alla luce è essenzialmente il processo inverso dell'adattamento al buio. Di fatto, i meccanismi fisiologici sottostanti sono gli stessi per entrambi i processi. Tuttavia, è importante considerarlo separatamente poiché le sue proprietà visive differiscono.

L'adattamento alla luce si verifica quando il livello di illuminazione viene aumentato. Pertanto, il sistema visivo deve diventare meno sensibile per produrre percezioni utili, dato che c'è molta più luce visibile disponibile. Questo sistema ha una gamma dinamica di uscita limitata disponibile per i segnali che le nostre percezioni producono. Tuttavia, il mondo reale ha livelli di illuminazione che coprono almeno 10 ordini di grandezza in più. Fortunatamente, è raro che abbiamo bisogno di visualizzare l'intera gamma di livelli di illuminazione nello stesso momento.
Ad alti livelli di illuminazione, l'adattamento si ottiene con lo sbiancamento del fotopigmento. Questo scala la cattura dei fotoni nei recettori e protegge la risposta del cono dalla saturazione causata da sfondi luminosi. I meccanismi di adattamento alla luce avvengono principalmente all'interno della retina [45]. Infatti, i cambiamenti del guadagno (gain) sono in gran parte specifici del singolo cono e l'adattamento raggruppa i segnali su aree aventi diametro non più grande dei singoli coni [46],[47]. Questo indica una localizzazione dell'adattamento alla luce che può avvenire già nei recettori. Tuttavia, sembra esserci più di un sito dove la sensibilità viene scalata. Alcuni dei cambiamenti di guadagno sono estremamente rapidi, mentre altri impiegano secondi o addirittura minuti per stabilizzarsi [48]. Di solito, l'adattamento alla luce richiede circa 5 minuti (sei volte più veloce dell'adattamento al buio). Questo potrebbe indicare l'influenza delle zone post-ricettive (post-receptive sites).
La figura soprastante mostra esempi di adattamento alla luce [43]. Se usassimo un'unica funzione per mappare l'ampia gamma di intensità nell'output del sistema visivo, avremmo solo una gamma molto piccola a nostra disposizione per una data scena. È chiaro che con una tale funzione, il contrasto percepito di una data scena sarebbe limitato e la sensibilità visiva ai cambiamenti sarebbe gravemente degradata a causa del rapporto segnale-rumore. Questo caso è mostrato dalla linea tratteggiata. Le linee solide invece rappresentano famiglie di risposte visive. Queste curve mappano la gamma di illuminazione di cui si può fare uso in una data scena nell'intera gamma dinamica dell'output visivo, ottenendo così la migliore percezione visiva possibile per ciascuna situazione. L'adattamento alla luce può essere pensato come il processo di scorrimento della curva di risposta visiva lungo l'asse del livello di illuminazione fino a raggiungere il livello ottimale per le condizioni visive date.
Adattamento cromatico modifica
Il concetto generale di adattamento cromatico consiste nella variazione dell'altezza delle tre curve di risposta spettrale dei coni. Questo adattamento si verifica perché l'adattamento alla luce avviene in modo indipendente all'interno di ciascuna classe di coni. Una formulazione specifica di questa ipotesi è conosciuta come l'adattamento di von Kries. Questa ipotesi afferma che la risposta di adattamento avviene in ciascuno dei tre tipi di cono separatamente ed è equivalente alla moltiplicazione delle loro sensibilità spettrali fisse per una costante che le scala [49]. Se i pesi di scala (noti anche come coefficienti di von Kries) sono inversamente proporzionali all'assorbimento della luce da parte di ciascun tipo di cono (cioè un assorbimento inferiore richiederà un coefficiente maggiore), allora la scala di von Kries mantiene una risposta media costante all'interno di ciascuna classe di coni. Questo fornisce un meccanismo semplice ma potente per mantenere il colore percepito degli oggetti nonostante i cambiamenti di illuminazione. In svariate condizioni diverse, la scalatura di von Kries fornisce un buon resoconto degli effetti dell'adattamento alla luce sulla sensibilità al colore e sull'aspetto [50],[51].
Il modo più semplice per immaginare l'adattamento cromatico è quello di esaminare un oggetto bianco sotto diversi tipi di illuminazione. Per esempio, prendiamo in considerazione un pezzo di carta sotto la luce del giorno, la luce fluorescente e l'illuminazione a incandescenza. La luce del giorno contiene relativamente più energia a lunghezza d'onda breve rispetto che la luce fluorescente, e l'illuminazione a incandescenza contiene relativamente più energia a lunghezza d'onda lunga della luce fluorescente. Tuttavia, nonostante le diverse condizioni di illuminazione, la carta mantiene approssimativamente il suo aspetto bianco sotto tutte e tre le fonti di luce. Questo perché il sistema del cono S diventa relativamente meno sensibile sotto la luce del giorno (per compensare l'addizionale energia a lunghezza d'onda breve) e il sistema del cono L diventa relativamente meno sensibile sotto l'illuminazione a incandescenza (per compensare l'energia aggiuntiva a lunghezza d'onda lunga)[43].
Note modifica
- ↑ 1,0 1,1 1,2 1,3 Bevil R Conway, Color vision, cones, and color-coding in the cortex, in The neuroscientist, vol. 15, 2009, pp. 274-290.
- ↑ Richard Russell e Pawan} Sinha, Real-world face recognition: The importance of surface reflectance properties, in Perception, vol. 36, n. 9, 2007.
- ↑ Karl R Gegenfurtner e Jochem Rieger, Sensory and cognitive contributions of color to the recognition of natural scenes, vol. 10, n. 13, 2000, pp. 805-808.
- ↑ Mark A Changizi, Qiong Zhang e Shinsuke Shimojo, Bare skin, blood and the evolution of primate colour vision, in Biology letters, vol. 2, n. 2, 2006, pp. 217-221.
- ↑ 5,0 5,1 Giordano Beretta, Understanding Color, Hewlett-Packard, 2000.
- ↑ 6,0 6,1 Robert M Boynton, Color vision, in Annual review of psychology, vol. 39, n. 1, 1988, pp. 69-100.
- ↑ Hermann Grassmann, Zur theorie der farbenmischung, in Annalen der Physik, vol. 165, n. 5, 1853, pp. 69-84.
- ↑ Arthur Konig e Conrad Dieterici, Die Grundempfindungen und ihre intensitats-Vertheilung im Spectrum, in Koniglich Preussischen Akademie der Wissenschaften, 1886.
- ↑ Vivianne C Smith e Joel Pokorny, Spectral sensitivity of the foveal cone photopigments between 400 and 500 nm, in Vision research, vol. 15, n. 2, 1975, pp. 161-171.
- ↑ JJ Vos e PL Walraven, On the derivation of the foveal receptor primaries, in Vision Research, vol. 11, n. 8, 1971, pp. 799-818.
- ↑ 11,0 11,1 11,2 Karl R Gegenfurtner e Daniel C Kiper, Color vision, in Neuroscience, vol. 26, n. 1, 2003, pp. 181.
- ↑ Peter K Kaiser e Robert M Boynton, Role of the blue mechanism in wavelength discrimination, in Vision research, vol. 125, n. 4, 1985, pp. 523-529.
- ↑ Walter Paulus e Angelika Kröger-Paulus, A new concept of retinal colour coding, in Vision research, vol. 23, n. 5, 1983, pp. 529-540.
- ↑ Janice L Nerger e Carol M Cicerone, The ratio of L cones to M cones in the human parafoveal retina, in Vision research, vol. 32, n. 5, 1992, pp. 879-888.
- ↑ Jay Neitz, Joseph Carroll, Yasuki Yamauchi, Maureen Neitz e David R Williams, Color perception is mediated by a plastic neural mechanism that is adjustable in adults, in Neuron, vol. 35, n. 4, 2002, pp. 783-792.
- ↑ Gerald H Jacobs, Gary A Williams, Hugh Cahill e Jeremy Nathans, Emergence of novel color vision in mice engineered to express a human cone photopigment, in Science, vol. 315, n. 5819, 2007, pp. 1723-1725.
- ↑ D Osorio, DL Ruderman e TW Cronin, Estimation of errors in luminance signals encoded by primate retina resulting from sampling of natural images with red and green cones, in JOSA A, vol. 15, n. 1, 1998, pp. 16-22.
- ↑ Daniel Kersten, Predictability and redundancy of natural images, in JOSA A, vol. 4, n. 112, 1987, pp. 2395-2400.
- ↑ I. T. Jolliffe, Principal Component Analysis, Springer, 2002.
- ↑ Gershon Buchsbaum e A Gottschalk, Trichromacy, opponent colours coding and optimum colour information transmission in the retina, in Proceedings of the Royal society of London. Series B. Biological sciences, vol. 220, n. 1218, 1983, pp. 89-113.
- ↑ Qasim Zaidi, Decorrelation of L-and M-cone signals, in JOSA A, vol. 14, n. 12, 1997, pp. 3430-3431.
- ↑ Daniel L Ruderman, Thomas W Cronin e Chuan-Chin Chiao, Statistics of cone responses to natural images: Implications for visual coding, in JOSA A, vol. 15, n. 8, 1998, pp. 2036-2045.
- ↑ BB Lee, PR Martin e A Valberg, The physiological basis of heterochromatic flicker photometry demonstrated in the ganglion cells of the macaque retina, in The Journal of Physiology, vol. 404, n. 1, 1998, pp. 323-347.
- ↑ 24,0 24,1 Andrew M Derrington, John Krauskopf e Peter Lennie, Chromatic mechanisms in lateral geniculate nucleus of macaque, in The Journal of Physiology, vol. 357, n. 1, 1984, pp. 241-265.
- ↑ Robert Shapley, Visual sensitivity and parallel retinocortical channels, in Annual review of psychology, vol. 41, n. 1, 1990, pp. 635--658.
- ↑ Karen R Dobkins, Alex Thiele e Thomas D Albright, Comparison of red--green equiluminance points in humans and macaques: evidence for different L: M cone ratios between species, in JOSA A, vol. 17, n. 3, 2000, pp. 545-556.
- ↑ Paul R Martin, Barry B Lee, Andrew JR White, Samuel G Solomon e Lukas Rüttiger, Chromatic sensitivity of ganglion cells in the peripheral primate retina, in Nature, vol. 410, n. 6831, 2001, pp. 933-936.
- ↑ VH Perry, R Oehler e A Cowey, Retinal ganglion cells that project to the dorsal lateral geniculate nucleus in the macaque monkey, in Neuroscience, vol. 12, n. 4, 1984, pp. 1101--1123.
- ↑ VA Casagrande, A third parallel visual pathway to primate area V1, in Trends in neurosciences, vol. 17, n. 7, 1994, pp. 305-310.
- ↑ Stewart HC Hendry e R Clay Reid, The koniocellular pathway in primate vision, in Annual review of neuroscience, vol. 23, n. 1, 2000, pp. 127-153.
- ↑ Edward M Callaway, Local circuits in primary visual cortex of the macaque monkey, in Annual review of neuroscience, vol. 21, n. 1, 1998, pp. 47-74.
- ↑ Bevil R Conway, Spatial structure of cone inputs to color cells in alert macaque primary visual cortex (V-1), in The Journal of Neuroscience, vol. 21, n. 8, 2001, pp. 2768-2783.
- ↑ Gregory D Horwitz e Thomas D Albright, Paucity of chromatic linear motion detectors in macaque V1, in Journal of Vision, vol. 5, n. 6, 2005.
- ↑ Marina V Danilova e JD Mollon, The comparison of spatially separated colours, in Vision research, vol. 46, n. 6, 2006, pp. 823-836.
- ↑ Thomas Wachtler, Terrence J Sejnowski e Thomas D Albright, Representation of color stimuli in awake macaque primary visual cortex, in Neuron, vol. 37, n. 4, 2003, pp. 681-691.
- ↑ Samuel G Solomon e Peter Lennie, Chromatic gain controls in visual cortical neurons, in The Journal of neuroscience, vol. 25, n. 19, 2005, pp. 4779-4792.
- ↑ David H Hubel, Eye, brain, and vision, Scientific American Library/Scientific American Books, 1995.
- ↑ Margaret S Livingstone e David H Hubel, Psychophysical evidence for separate channels for the perception of form, color, movement, and depth, in The Journal of Neuroscience, vol. 7, n. 11, 1987, pp. 3416-3468.
- ↑ Semir M Zeki, Colour coding in rhesus monkey prestriate cortex, in Brain research, vol. 53, n. 2, 1973, pp. 422-427.
- ↑ Bevil R Conway e Doris Y Tsao, Color architecture in alert macaque cortex revealed by fMRI, in Cerebral Cortex, vol. 16, n. 11, 2006, pp. 1604-1613.
- ↑ Roger BH Tootell, Koen Nelissen, Wim Vanduffel e Guy A Orban, Search for color 'center(s)'in macaque visual cortex, in Cerebral Cortex, vol. 14, n. 4, 2004, pp. 353-363.
- ↑ Bevil R Conway, Sebastian Moeller e Doris Y Tsao, Specialized color modules in macaque extrastriate cortex, in 560--573, vol. 56, n. 3, 2007, pp. 560-573.
- ↑ 43,0 43,1 43,2 43,3 Mark D Fairchild, Color appearance models, John Wiley & Sons, 2013.
- ↑ Michael A Webster, Human colour perception and its adaptation, in Network: Computation in Neural Systems, vol. 7, n. 4, 1996, pp. 587 - 634.
- ↑ Robert Shapley e Christina Enroth-Cugell, Visual adaptation and retinal gain controls, in Progress in retinal research, vol. 3, 1984, pp. 263-346.
- ↑ A Chaparro, CF Stromeyer III, G Chen e RE Kronauer, Human cones appear to adapt at low light levels: Measurements on the red-green detection mechanism, in Vision Research, vol. 35, n. 22, 1995, pp. 3103-3118.
- ↑ Donald IA Macleod, David R Williams e Walter Makous, A visual nonlinearity fed by single cones, in Vision research, vol. 32, n. 2, 1992, pp. 347-363.
- ↑ Mary Hayhoe, Adaptation mechanisms in color and brightness, Springer, 1991.
- ↑ David L MacAdam, Sources of Color Science, MIT Press, 1970.
- ↑ Michael A Webster e JD Mollon, Colour constancy influenced by contrast adaptation, in Nature, vol. 373, n. 6516, 1995, pp. 694-698.
- ↑ David H Brainard e Brian A Wandell, Asymmetric color matching: how color appearance depends on the illuminant, in JOSA A, vol. 9, n. 9, 1992, pp. 1443-1448.