Protocolli e architetture di instradamento/Filtraggio dei pacchetti basato su software
Il software in grado di analizzare i campi nei pacchetti trova spazio, eseguito su circuiti integrati o microprocessori, in varie applicazioni:
- switch: gli algoritmi di apprendimento si basano sugli indirizzi MAC sorgente e di destinazione delle trame, e l'inoltro delle trame si basa sugli indirizzi MAC di destinazione;
- router: l'inoltro dei pacchetti si basa sugli indirizzi IP sorgente e di destinazione;
- firewall: se una regola basata sui campi del pacchetto è soddisfatta, lancia l'azione associata di filtraggio (ad es. scarta);
- NAT: converte gli indirizzi IP tra privati e pubblici e le porte TCP/UDP di ogni pacchetto in transito;
- URL filter: blocca il traffico HTTP da/verso URL di siti Web in una black list;
- pila protocollare: il sistema operativo consegna il pacchetto alla pila di livello rete appropriata (ad es. IPv4 o IPv6), poi il pacchetto passa alla pila di livello trasporto appropriata (ad es. TCP o UDP), infine in base alla quintupla che identifica la sessione il pacchetto viene reso disponibile all'applicazione attraverso il socket giusto;
- cattura dei pacchetti: le applicazioni per la cattura del traffico (ad es. Wireshark, tcpdump) possono impostare un filtro per ridurre la quantità di pacchetti catturati.
Architettura tipica di un sistema di filtraggio dei pacchetti
modifica
- Componenti di livello kernel
- network tap: intercetta i pacchetti dalla scheda di rete e li consegna a una o più[1] pile di filtraggio;
- packet filter: lascia passare solo i pacchetti che soddisfano il filtro specificato dall'applicazione di cattura, aumentando l'efficienza della cattura: i pacchetti non voluti vengono scartati subito, e nel kernel buffer viene copiato un minor numero di pacchetti;
- kernel buffer: memorizza i pacchetti prima che vengano consegnati al livello user;
- API di livello kernel: fornisce al livello user le primitive, tipicamente chiamate di sistema
ioctl, necessarie per accedere ai livelli sottostanti.
- Componenti di livello user
- user buffer: memorizza i pacchetti nello spazio di indirizzamento dell'applicazione utente;
- libreria di livello user (ad es. libpcap, WinPcap): esporta delle funzioni che sono mappate con le primitive fornite dalla API di livello di kernel, e fornisce un compilatore di alto livello per creare al volo il codice pseudo-assembler da iniettare nel packet filter.
Principali sistemi di filtraggio dei pacchetti
modificaCSPF
modificaIl CMU/Stanford Packet Filter (CSPF, 1987) fu il primo packet filter, ed era implementato in parallelo alle altre pile protocollari.
Introdusse alcune migliorie chiave:
- implementazione a livello kernel: l'elaborazione è più veloce perché si evita il costo della commutazione di contesto tra il kernel space e lo user space, anche se è più facile danneggiare l'intero sistema;
- packet batching: il kernel buffer non consegna subito un pacchetto arrivato all'applicazione, ma aspetta che ne siano memorizzati un certo numero e poi li copia tutti insieme nello user buffer per ridurre il numero di commutazioni di contesto;
- macchina virtuale: i filtri non sono più hard-coded, ma il codice di livello user può istanziare in fase di esecuzione un pezzo di codice in linguaggio pseudo-assembler che specifica le operazioni di filtraggio per determinare se il pacchetto può passare o deve essere scartato, e una macchina virtuale nel packet filter, composta in pratica da uno
switch casesu tutte le istruzioni possibili, emula un processore che interpreta quel codice per ogni pacchetto in transito.
BPF/libpcap
modificaIl Berkeley Packet Filter (BPF, 1992) fu la prima implementazione seria di un packet filter, adottato storicamente dai sistemi BSD e usato ancora oggi in coppia con la libreria libpcap in user space.
- Architettura
- network tap: è integrata nel driver della NIC, e può essere chiamata con esplicite chiamate ai componenti di cattura;
- kernel buffer: è suddiviso in due aree di memoria separate, in modo che i processi di livello kernel e di livello user possano operare in modo indipendente (il primo scrive mentre il secondo legge) senza necessità di sincronizzazione sfruttando due core della CPU in parallelo:
- lo store buffer è l'area in cui scrive il processo di livello kernel;
- l'hold buffer è l'area da cui legge il processo di livello user.
NPF/WinPcap
modificaLa libreria WinPcap (1998), sviluppata inizialmente al Politecnico di Torino, può essere considerata un porting per Windows dell'intera architettura BPF/libpcap.
- Architettura
- Netgroup Packet Filter (NPF): è il componente di livello kernel e include:
- network tap: giace sopra i driver della NIC, registrandosi come nuovo protocollo di livello rete accanto ai protocolli standard (come IPv4, IPv6);
- packet filter: la macchina virtuale è un compilatore just in time (JIT): invece di interpretare il codice, lo traduce in istruzioni native del processore x86;
- kernel buffer: è implementato come un buffer circolare: i processi di livello kernel e di livello user scrivono nella stessa area di memoria, e il processo di livello kernel sovrascrive i dati già letti dal processo di livello user → ottimizza lo spazio in cui memorizzare i pacchetti, ma:
- se il processo di livello user è troppo lento a leggere i dati, il processo di livello kernel potrebbe sovrascrivere dei dati non ancora letti (cache pollution) → è necessaria la sincronizzazione tra i due processi: il processo scrivente deve ispezionare periodicamente una variabile condivisa contenente la posizione di lettura corrente;
- l'area di memoria è condivisa tra i core della CPU → il buffer circolare è meno efficiente dal punto di vista della CPU;
- Packet.dll: esporta a livello user delle funzioni, indipendenti dal sistema operativo, che sono mappate con le primitive fornite dalla API di livello di kernel;
- Wpcap.dll: è la libreria a collegamento dinamico con cui l'applicazione interagisce direttamente:
- offre al programmatore le funzioni di libreria di alto livello necessarie per accedere ai livelli sottostanti (ad es.
pcap_open_live(),pcap_setfilter(),pcap_next_ex()/pcap_loop()); - include il compilatore che, dato un filtro definito dall'utente (ad es. stringa
ip), crea il codice pseudo-assembler (ad es. "se il campo 'EtherType' è uguale a 0x800 restituisci vero") da iniettare nel packet filter per il compilatore JIT; - implementa lo user buffer.
- offre al programmatore le funzioni di libreria di alto livello necessarie per accedere ai livelli sottostanti (ad es.
- Nuove funzionalità
- statistics mode: registra dati statistici nel kernel senza commutazioni di contesto;
- packet injection: invia pacchetti attraverso l'interfaccia di rete;
- remote capture: attiva un server remoto che cattura i pacchetti e li consegna localmente.
Ottimizzazioni prestazionali
modifica- Evoluzione delle tecniche di ottimizzazione delle prestazioni.
-
 Architettura tradizionale.
Architettura tradizionale. -
 Architettura con shared buffer.
Architettura con shared buffer. -
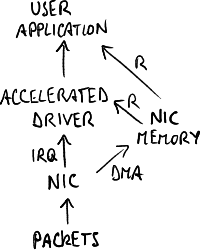 Architettura con driver accelerato.
Architettura con driver accelerato.



Negli ultimi anni il traffico sulle reti è cresciuto più velocemente rispetto alle prestazioni dei computer (memoria, CPU). Le prestazioni dell'elaborazione dei pacchetti possono essere migliorate in vari modi:
- incrementare le prestazioni della cattura: migliorare la capacità di recapito dei dati al software;
- creare componenti di analisi più intelligenti: solamente i dati più interessanti vengono recapitati al software (ad es. l'URL per un URL filter);
- ottimizzare l'architettura: cercare di sfruttare le caratteristiche dell'applicazione per migliorare le prestazioni.
- Dati di profiling (WinPcap 3.0, pacchetti da 64 byte)
- [49,02%] driver NIC e sistema operativo: quando entra nella NIC, il pacchetto impiega un sacco di tempo solo per arrivare alla pila di cattura:
- la NIC trasferisce il pacchetto nella sua zona di memoria kernel tramite DMA (non usa la CPU);
- la NIC lancia un \textbf{interrupt} (IRQ) al driver della NIC, interrompendo il programma correntemente in esecuzione;
- il driver della NIC copia il pacchetto dalla memoria della NIC in una zona di memoria kernel del sistema operativo (usa la CPU);
- il driver della NIC invoca il sistema operativo cedendo il controllo ad esso;
- il sistema operativo chiama le varie pile protocollari registrate, incluso il driver di cattura;
- [17,70%] tap processing: operazioni svolte dal driver di cattura al principio della pila di cattura (ad es. ricevere i pacchetti, impostare gli interrupt);
- [8,53%] timestamping: al pacchetto viene associato il timestamp;
- [3,45%] packet filter: i costi di filtraggio sono proporzionalmente bassi grazie al compilatore JIT;
- doppia copia nei buffer: il costo delle copie aumenta tanto più i pacchetti sono grandi:
- [9,48%] copia nel kernel buffer: il pacchetto è copiato dalla memoria del sistema operativo al kernel buffer;
- [11,50%] copia nello user buffer: il pacchetto è copiato dal kernel buffer allo user buffer;
- [0,32%] commutazione di contesto: ha un costo insignificante grazie al packet batching.
Interrupt
modificaIn tutti i sistemi operativi, ad un certo input rate la percentuale di pacchetti che arrivano all'applicazione di cattura non solo non aumenta più, ma diminuisce drasticamente a causa del livelock: gli interrupt sono così frequenti che il sistema operativo non ha il tempo di leggere i pacchetti dalla memoria della NIC e copiarli nel kernel buffer per consegnarli all'applicazione → il sistema è vivo e sta facendo del lavoro, ma non sta facendo del lavoro utile.
Esistono varie soluzioni per abbattere il costo degli interrupt:
- interrupt mitigation (basato su hardware): viene scatenato un interrupt solo quando è stato ricevuto un certo numero di pacchetti (un timeout evita la starvation se la soglia minima non è raggiunta entro un certo tempo);
- interrupt batching (basato su software): quando arriva un interrupt, il sistema operativo serve il pacchetto arrivato e poi lavora in modalità polling: serve immediatamente i pacchetti successivi arrivati nel frattempo, fino a quando non ci sono più pacchetti e l'interrupt può essere riabilitato sulla scheda;
- device polling (ad es. BSD [Luigi Rizzo]): il sistema operativo non attende più un interrupt, ma controlla autonomamente con un ciclo infinito la memoria della NIC → siccome un core della CPU è perennemente impegnato nel ciclo infinito, questa soluzione è adatta quando sono necessarie prestazioni veramente elevate.
Timestamping
modificaEsistono due soluzioni per ottimizzare il timestamping:
- timestamp approssimato: il tempo reale è letto solo ogni tanto, e il timestamp è basato sul numero di cicli di clock trascorsi dall'ultima lettura → il timestamp dipende dalla frequenza di clock del processore, e i processori hanno frequenze di clock sempre maggiori;
- timestamp hardware: il timestamp è implementato direttamente nella scheda di rete → i pacchetti arrivano al software già dotati di timestamp.
Copia nello user buffer
modificaLa zona di memoria kernel in cui è presente il kernel buffer viene mappata in user space (ad es. tramite nmap()) → la copia dal kernel buffer allo user buffer non è più necessaria: l'applicazione può leggere il pacchetto direttamente dallo shared buffer.
- Implementazione
Questa soluzione è adottata in nCap di Luca Deri.
- Problemi
- sicurezza: l'applicazione accede a delle zone di memoria kernel → può danneggiare il sistema;
- indirizzamento: il kernel buffer è visto attraverso due spazi di indirizzamento differenti: gli indirizzi usati in kernel space sono diversi dagli indirizzi usati in user space;
- sincronizzazione: l'applicazione e il sistema operativo devono lavorare su variabili condivise (ad es. le posizioni di lettura e scrittura dei dati).
Copia nel kernel buffer
modificaIl sistema operativo non è fatto per supportare un grande traffico di rete, ma è stato ingegnerizzato per eseguire applicazioni utente con un limitato consumo di memoria. Prima di arrivare alla pila di cattura, ogni pacchetto è memorizzato in un'area di memoria del sistema operativo che è allocata dinamicamente come una lista linkata di piccoli buffer (mbuf in BSD e skbuf in Linux) → il costo di allocazione e di liberazione dei mini-buffer è troppo oneroso rispetto a un grande buffer allocato staticamente in cui memorizzare pacchetti di qualsiasi dimensione.
Le schede dedicate alla cattura non sono più viste dal sistema operativo, ma usano driver accelerati inglobati nella pila di cattura: la NIC copia il pacchetto nella sua zona di memoria kernel, e l'applicazione legge direttamente da quella zona di memoria senza l'intermediazione del sistema operativo.
- Implementazioni
Questa soluzione è adottata in netmap di Luigi Rizzo e in DNA di Luca Deri.
- Problemi
- applicazioni: le altre pile protocollari (ad es. pila TCP/IP) sono scomparse → la macchina è completamente dedicata alla cattura;
- sistema operativo: è richiesta una modifica intrusiva al sistema operativo;
- NIC: il driver accelerato è fortemente legato alla NIC → non è possibile usare un altro modello di NIC;
- prestazioni: il collo di bottiglia rimane la banda del bus PCI;
- timestamp: non è preciso a causa dei ritardi dovuti al software.
Commutazione di contesto
modificaL'elaborazione è spostata in kernel space, evitando la commutazione di contesto allo user space.
- Implementazione
Questa soluzione è adottata nel Data Plane Development Kit (DPDK) di Intel, con lo scopo di realizzare apparati di rete programmabili via software su hardware Intel.
- Problemi
- packet batching: il costo della commutazione di contesto è ridicolo grazie al packet batching;
- debug: è più facile in user space;
- sicurezza: l'intera applicazione lavora con memoria kernel;
- programmazione: è più difficile scrivere il codice nel kernel space.
NIC intelligenti
modificaL'elaborazione è svolta direttamente dalla NIC (ad es. Endace):
- elaborazione hardware: evita il collo di bottiglia del bus PCI, limitando lo spostamento dei dati (anche se il miglioramento prestazionale è limitato);
- precisione del timestamp: non c'è il ritardo dovuto al software ed è basato sul GPS → queste NIC sono adatte per catture su reti geograficamente estese.
Parallelizzazione in user space
modificaFFPF ha proposto un'architettura che cerca di sfruttare le caratteristiche dell'applicativo per andare più veloce, aumentando il parallelismo in user space: l'applicazione di cattura è multi-thread ed è eseguita su CPU multi-core.
L'hardware può aiutare la parallelizzazione: la NIC può registrarsi al sistema operativo con più adapter, e ciascuno di essi è una coda logica distinta da cui escono i pacchetti a seconda della classificazione, effettuata da filtri hardware, in base ai loro campi (ad es. indirizzi MAC, indirizzi IP, porte TCP/UDP) → più software possono leggere da code logiche distinte in parallelo.
- Applicazioni
- receive side scaling (RSS): la classificazione è basata sull'identificativo di sessione (quintupla) → tutti i pacchetti appartenenti alla stessa sessione vanno alla stessa coda → è possibile bilanciare il carico sui server Web:
 B8. Content Delivery Network#Server load balancing;
B8. Content Delivery Network#Server load balancing; - virtualizzazione: ogni macchina virtuale (VM) su un server ha un indirizzo MAC diverso → i pacchetti entrano direttamente nella VM giusta senza essere toccati dal sistema operativo (hypervisor): C3. Introduzione alle Software-Defined Network#Network Function Virtualization.
Note
modifica- ↑ Ogni applicazione di cattura ha la sua pila di filtraggio, ma tutte condividono la stessa network tap.